
Understanding Analytics Part 1: Top Internal Sources of Big Data
There’s no arguing the power of big data in today’s corporate landscape. Businesses are analyzing a seemingly endless array of data sources in order to glean insights into just about every activity – both inside their business, as well as those that are customer-facing. Right now, it seems that enterprises cannot get their hands on enough big data for analysis purposes – the opportunities and advantages to be had here are tempting, as well as actionable, and can really make all the difference for today’s companies.
However, as corporations’ hunger for data grows, so too does their search for usable data sources. There are several places where businesses can gather and collect big data, both inside and outside of their own organizations. Currently, there are a more than a few data brokers that will sell lists of information – and while these may seem helpful, it’s up to the enterprise to analyze and make the best use of this data.
What’s more, without the proper knowledge, skills and support, these lists can be incredibly ineffective and, therefore, not worth the investment. Before businesses turn to data brokers, there are a few key places that they can look to gather their own big data. Let’s take a look at some of the top informational sources, and how these can benefit your organization, no matter what industry you operate in.
Internal vs. external
Before we get into the specific sources themselves, it’s important to understand the main classification of these datasets. Overall, there are two main categories that big data can fall under: internal or external.
“Internal sources of data reflect those data that are under the control of the business,” Customer Think contributor and data scientist Bob Hayes explained. “External data, on the other hand, are any data generated outside the wall of the business.”
In this way, internal data is the information that the business already has on hand, has control of and currently owns, including details contained within the company’s own computer systems and cloud environments. External data is information that is not currently owned by the company, and can include unstructured, public data as well as information gathered by other organizations.
Today, we’ll take a deep dive into internal data sources, including those that are currently controlled by the organization under its own roof.
Internal data: Company-owned information systems
Before decision-makers and data scientists look for external sources, it’s critical to ensure that all of a business’s internal data sources are mined, analyzed and leveraged for the good of the company. While external data can offer a range of benefits that we’ll get into later, internal data sources are typically easier to collect and can be more relevant for the company’s own purposes and insights.
There are a number of impactful, internal places that companies can look to mine data. These include:
- Transactional data and POS information: One of the most powerful sources of data resides within a firm’s financial and transactional systems. Here, companies can mine both current and historical data relating to their own business purchases, as well as information relating to the shopping trends of their customers. From these details, an organization can glean important insights, including ways to reduce their own spending and remain on budget, as well as crucial patterns pertaining to their customers’ buying habits and shopping preferences.
- Customer relationship management system: In addition to their purchasing and shopping data, businesses can also mine data within their own CRM systems. Information like clients’ company affiliations, locations and other regional or geographical details can paint a detailed picture about where customers are located. When combined with their transactional information, these CRM details become even more powerful.
- Internal documents: Especially now within the age of cloud computing, a company’s own internal documents are becoming more valuable than ever. Digitized copies of internal forms can provide a robust source of information, particularly when it comes to the business’s activities, policies and processes. Kapow Software noted in an infographic that emails, Word documents, PDF, XML and a range of other internal docs can be mined for big data.
- Archives: When it comes to internal information, businesses shouldn’t limit themselves to only the most current information. Historical data can be very telling as well, which is why Kapow Software recommends looking into the company’s archived documents and data streams as well.
- Other business applications: While CRM is one of the most robust internal sources of big data, this doesn’t mean that other internal applications cannot be mined. Other platforms that employee users leverage, including project management, marketing, productivity, enterprise resource management, human resources, expense management as well as automation apps can be incredibly beneficial as well. When mining these sources, it’s in a company’s best interest to let the nature of their big data initiative drive their decisions surrounding which sources to utilize. For example, if an organization is looking to gain insight about the current budget, sources like expense tracking and resource management will be the most helpful.
- Device sensors: The Internet of Things is growing every day, and providing additional and increasingly unique data for analysis. Companies that utilize devices that are equipped with sensors and network connectivity can leverage these for data as well. These include IoT items that the business uses in its own office, or those that it provides for its customers. For instance, car sensors on an enterprise’s fleet of vehicles can offer a wealth of data about usage, mileage, gas and traveling expenses. Companies that offer fitness or other health sensors can gather, anonymize and analyze these sources as well.
“Internal data sources are typically easier to collect and can be more relevant.”
Internal big data: Answering the big questions
Overall, internal sources of big data can offer numerous advantages for today’s businesses. Not only are these sources incredibly telling and relevant, but they’re free of cost to the company, as this is information that the organization already owns. In this way, enterprises can launch an array of big data initiatives without ever looking beyond their own walls.
However, when it comes to analyzing these sources, it’s best to have an industry-leading partner like Aunalytics that can help your firm answer the big questions. Aunalytics specializes in big data analysis, and can help pinpoint the source that will provide the most valuable and competitive advantage for your company. To find out more, contact Aunalytics today.
And check out the second part of this series, where we investigate the top external sources of big data, and how these can be best utilized.

What Can Clickstream Data Tell You About Your business?
Today, more businesses leverage big data to inform important decisions than ever before. This information can come from a range of different sources, each of which paints an insightful new picture of the company, its customers or both. However, in order to reap these benefits, organizations must not only have the data itself, but the skills and understanding to analyze and apply it in the best way possible.
One of the most revealing sources here is clickstream data, which can offer numerous advantages for businesses.
What, exactly, is clickstream data?
Before we get into the actual application of clickstream data, it's important to understand what this information is and where it comes from.
Clickstream data can be thought of as a roadmap of a user's online activity. This information represents digital breadcrumbs that show what websites a user has visited, what pages they viewed on that site, how long they spent on each page and where they clicked next.
"A clickstream is the recording of what a user clicks while browsing the web," Mashable explained. "Every time he or she clicks on a link, an image, or another object on the page, that information is recorded and stored. You can find out the habits of one individual, but more useful is when you record thousands of clickstreams and see the habits and tendencies of your users."
Clickstreams can be stored on the server that supports a website, as well as by a user's own web browser. In addition, internet service providers and online advertising networks also have the capability to record and store clickstream information.
What's included in clickstream information?
Diving a little deeper here, there are a range of insights clickstream data can offer, starting at the beginning of a user's journey.
For instance, clickstream information can show what terms an individual plugged into a search engine in order to reach the company's page. These details can reveal any other websites the user might have visited before reaching the business's website. Once the visitor has reached the site, clickstream data can show what page the person first landed on, what features or capabilities he or she clicked on once there, how much time was spent on that page and where the online journey took him or her after that page.
But clickstream data doesn't end there. In addition to revealing which pages a user visited and in what order, this information can also show any use of the "back" button, as well as when and where items were added or removed from a shopping cart.
While clickstreams do not include personal details of the users themselves, when collected and analyzed, this information can be applied to numerous improvements to the company's website and overall online presence.
Applying clickstream analysis: How can my business benefit?
There are several ways businesses can make use of clickstream analysis, including to enhance the experience users have with the brand. Let's take a look:
1. Identifying customer trends: Thanks to clickstream information, companies can see the path customers have taken in order to get to their site. By collecting and analyzing the clickstreams of a large number of customers, an enterprise can identify certain similarities and trends that they can leverage to the organization's advantage. For instance, if a majority of users utilized the same search term to reach a site that led them to the brand's website, the company can eliminate the middle man and ensure that their site is optimized for that search term.
2. Different pathways lead to the same destination: Clickstream data can also be leveraged to view the different routes customers might have taken to reach a product page.
"Just as drivers can take different roads to arrive at the same destination, customers take different paths online and end up buying the same product," Qubole noted. "Basket analysis helps marketers discover what interests customers have in common, and the common paths they took to arrive at a specific purchase."
Using these details, the company can look to create the most efficient path possible for customers, ensuring that they quickly and effectively locate the product they're looking for and can easily complete their purchase.
3. Preventing abandonment: In addition to "cart abandonment," analyzing the positive website interactions, clickstream data can also reveal the top pages where the most visitors leave the site. For instance, if a large number of users exit the site on a certain page, it could be very telling about the page itself. It could be that a feature on that page isn't working as it should, or the website is asking users for information that they aren't ready to give at that juncture. Whatever the reason, clickstream can show which pages on a site may need extra attention and improvement.
Best of all, this is only the beginning when it comes to clickstream data. These details can reveal even more when they belong to registered users - here, demographic information is made available, enabling the company to create targeted ads and other, more personalized offers.
Clickstream data can be incredibly powerful for today's companies, but only if firms have the skills and resources necessary to capture, collect and analyze this information. Aunalytics is a top expert in this field, providing the technology necessary to support clickstream analysis. To find out more about how this process can benefit your business's unique needs, contact the experts at Aunalytics today.

The Internet of Things: Challenges, Insights, & The Future
This month, we sat down with Aunalytics’ Vice President of Predictive Modeling, David Cieslak, PhD, to discuss his work on Internet of Things (IoT) analysis. We talked about the unique challenges of this type of project and what he’s learned, interesting insights he has discovered, and his thoughts on the future of the IoT field.
Q: How does an IoT project differ from other kinds of machine learning problems you have faced, and how are they similar? Are there differences within the data itself? Do you tend to use different methods of analysis
DC: It is exciting for Aunalytics to engage in the Internet of Things. A data scientist or machine learning researcher is especially captivated by this kind of problem for a variety of reasons. Beyond working on a high profile, cutting-edge area that brings a lot of hype and excitement, IoT data is very rich. Like responsibly collected web traffic utilized in clickstream analysis, a data scientist can walk into an IoT project with reasonable assumptions for high levels of data capture and information quality as data is being collected via autonomous, digital sensors. Such sensors do a good job of collecting a variety of data points pertaining to device operation, location, and user interaction. These values are often logically and consistently encoded; in some cases they are tailor-made with analytics or data science in mind. The implication is that a data scientist can often assume a higher starting point.
While the overall signal quality often presents a better opportunity, such a challenge can put a data scientist’s quantitative skills and creativity to the test. Algorithmically, data scientists might be asked to get out of their comfort zone and utilize advanced signal processing methods in order to provide digestible information. Likewise, time series analysis and anomaly detection feature more heavily in the IoT domain. Whereas hand-crafted featurization was often sufficient for other types of projects, IoT almost necessitates advanced, automated quantization strategies in order to keep up with the pace of data and business. The rules of the IoT game are being written in-flight and it’s critical for a data scientist to be able to learn and adapt to what works and what doesn’t, particularly within this domain. This requires the ability to understand contributions from many different engineering and mathematical disciplines and leveraging prior work from a variety of sources while simultaneously boiling down complexity without making the subject matter overly simplistic.
Q: What specific challenges have you faced in terms of analysis of device data? What lessons have you learned so far?
DC: The biggest issue surrounding IoT data is scale. Historically, a “more is better” approach has been taken with regards to logging, but this can have very practical implications on analysis. Sensors on an IoT enabled device might generate a status snapshot every second or even more frequently. Even a single record generated every second means that you’ll be responsible for storing and processing 86,400 records of data per device every day. If you have a fleet of 10 devices generating 10 pieces of data in every snapshot, it’s easy to imagine how quickly 8.6 million daily records can begin to saturate even the bulkiest big data solutions available. Whereas data scientists have typically been begging for more data, it’s very easy to see how they might drown in this environment. One very real decision that must be made is to determine what data is collected and how often and whether any sampling must be done in order to accommodate analysis. As always, this depends on the application and the availability of data processing resources. Sampling fridge sensors every 5 minutes might lead to a miss in temperature spikes that cause your $50 Ahi steak to go bad. Sampling a subset of vehicle dynamics every 5 minutes might miss a rapidly evolving failure and lead to a fatal accident.
Relatedly, it can be very challenging to boil down a lot of data to the audience. While this is a pervasive challenge in data science, the temporal nature of the signals we’re receiving mean that it’s even more challenging for a data scientist to translate a relevant, high-level inquiry into something structured and measurable. This puts a lot of responsibility on a data scientist to have a sufficiently broad and workable “statistical vocabulary” to satisfy highly curious audiences.
Q: What kinds of “insights” have you been able to uncover with clients?
DC: So far, we’ve looked at IoT through a lens of consumer products. This focus has led us to uncover interesting utilization patterns. Our customers have invested heavily into engineering product features development but what we find is that in many instances customers lock into a small subset and use them habitually. The good news is that the utilized features are often fairly unique per customer, so few features are truly going to waste. This also represents an opportunity for our clients to develop outreach programs for better product education.
While product and engineering research is important, this can also translate into savings for the customer as well. Depending on where they live, they might be able to save money on their electrical bill by using appliances at specific points in the day. Likewise, business experts may be able to help clients use their devices in ways to save them money.
We’re also identifying frustration events in the data, typically where we’re observing “jamming patterns” where particular buttons are pressed obsessively over a short period of time. Likewise, we’re working to identify how sensory signals can be utilized to predict device failure, enabling a potentially interventionist strategy.
Q: What do you see as some of the most exciting developments in IoT so far?
DC: Overall, I’m excited to see many consumer durables and home goods entering the IoT breech. There are many gains to be made from power and environmental savings as well as safety by having such appliances monitored.
IoT has significant potential in fitness and health. EMR systems are largely incidence based—they track information when a patient has a problem, but fitness devices offer an opportunity for broadening an otherwise sparse dataset by quantifying fitness before a health incidence occurs.
There are significant opportunities for IoT within critical infrastructure pieces for our country and the world. Public transportation such as trains and planes stand to benefit from superior safety monitoring. Better monitoring can lead to alterations in operating policies which can also lead to better energy efficiencies. There are tremendous benefits within agriculture as well—farmers can now do a better job of tracking their crop “in flight,” meaning critical growth is at reduced risk for failure. These are only some of the ways that IoT technologies are being applied today.
Q: Where do you see this field going in the future?
DC: IoT is also a useful testbed for a broad class of robotics. Never before have we been able to collect so much data on behavior and activities at such a micro-level. Many of the biggest informatic developments of the last 20 years have been bootstrapped by creating data collection and tagging schemas, such as video and audio signal processing. In turn, collecting such voluminous data will enable robotics research to develop even better understandings of human interactions and activity, and allow them to make significant gains in this area over the next 20 years. Another rising area is Population Health, where we will develop better understandings of the influx of patients into particular healthcare facilities and practices.
Building a Data Warehouse
To perform interesting predictive or historical analysis of ever-increasing amounts of data, you first have to make it small. In our business, we frequently create new, customized datasets from customer source data in order to perform such analysis. The data may already be aggregated, or we may be looking at data across disparate data sources. Much time and effort is spent preparing this data for any specific use case, and every time new data is introduced or updated, we must build a cleaned and linked dataset again.
To streamline the data preparation process, we’ve begun to create data warehouses as an intermediary step; this ensures that the data is aggregated into a singular location and exists in a consistent format. After the data warehouse is built, it is much easier for our data scientists to create customized datasets for analysis, and the data is in a format that less-technical business analysts can query and explore.
Data warehouses are not a new concept. In our last blog post, we talked about the many reasons why a data warehouse is a beneficial method for storing data to be used for analytics. In short, a data warehouse can improve the efficiency of our process by creating a structure for aggregated data and allows data scientists and analysts to more quickly get the specific data they need for any analytical query.
A data warehouse is defined by its structure and follows these four guiding principles:
- Subject-oriented: The structure of a data warehouse is centered around a specific subject of interest, rather than as a listing of transactions organized by timestamps.
- Integrated: In a data warehouse, data from multiple sources is integrated into a single structure and consistent format.
- Non-volatile: A data warehouse is a stable system; it is not constantly changing.
- Time-variant: The term “time-variant” refers to the inclusion of historical data for analysis of change over time.
These principles underlie the data warehouse philosophy, but how does a data warehouse work in practice? We will explore two of the more concrete aspects of a data warehouse: how the data is brought into the warehouse, and how the data may be structured once inside.
Data Flow into a Warehouse
Most companies have data in various operational systems; marketing databases, sales databases, and even external data purchased from vendors. They may even have a data warehouse of their own for certain areas of their business. Unfortunately, it is next to impossible to directly compare data across various locations. In order to do such analysis, a great amount of effort is needed to get the data onto a common platform and into a consistent format.
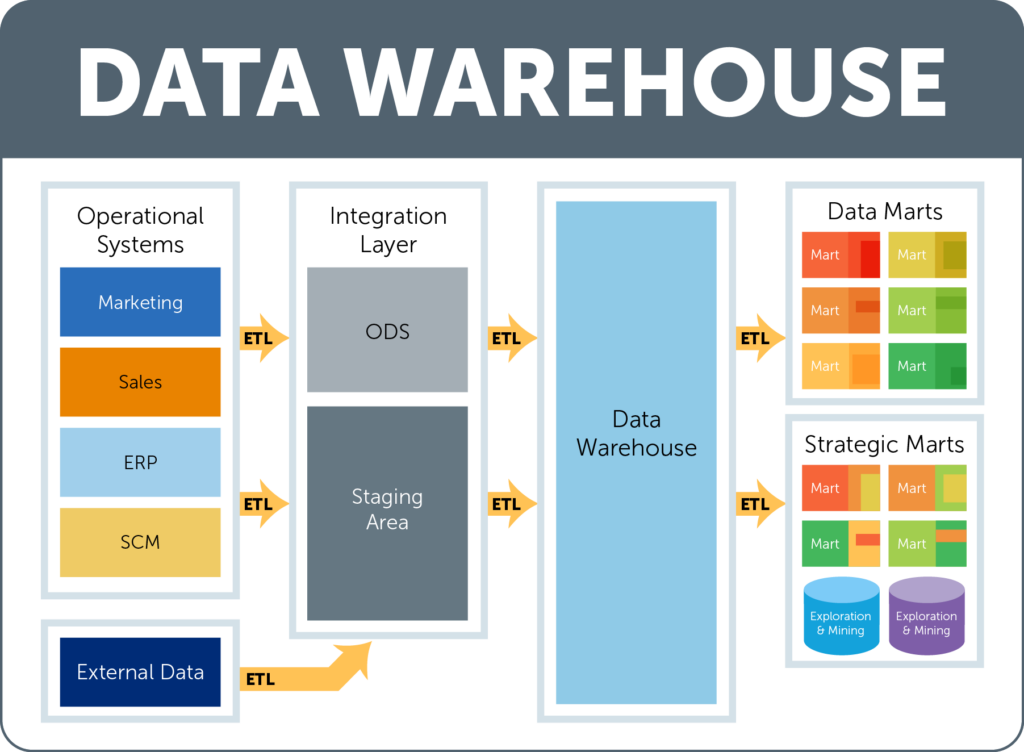
First, these disparate data sources must be combined into a common location. The data is initially brought to an area known as the integration layer. Within the integration layer, there is an ODS (operational data store) and a staging area, which work together (or independently at times) to hold, transform, and perform calculations on data prior to the data being added to the data warehouse layer. This is where the data is organized and put into a consistent format.
Once the data is loaded into the data warehouse (the structure of which we will discuss later on in the blog post), it can be accessed by users through a data mart. A data mart is a subset of the data that is specific to individual department or users and includes only the data that is most relevant to their specific use cases. There can be multiple data marts, but they all pull from the same data warehouse to ensure that the information that is seen is the most up-to-date and accurate. Many times, in addition to marts, a data warehouse will have databases specially purposed for exploration and mining. A data scientist can explore the data in the warehouse this way, and generate custom datasets on an analysis-by-analysis basis.
At every step of the way, moving the data from one database to another involves using a series of operations known as ETL, which stands for extract, transform, and load. First, the data must be extracted from the original source. Next, that data is transformed into a consistent format, and finally, the data is loaded into the target database. These actions are performed in every step of the process.
Data Warehouse Structure
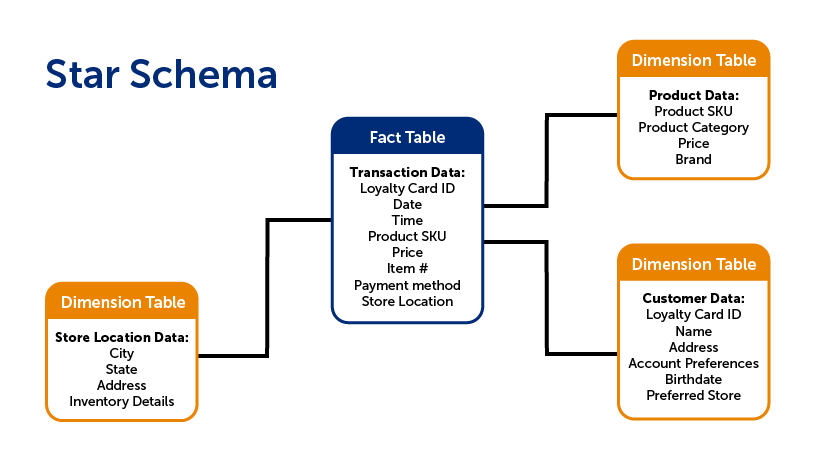
There are a few different ways that the data within the warehouse can be structured. A common way to organize the data is to use what is called a star schema. A star schema is composed of two types of tables: fact tables and dimension tables.
Fact tables contain data that corresponds to a particular business practice or event. This would include transaction details, customer service requests, or product returns, to name a few. The grain is the term for the level of detail of the fact table. For instance, if your fact table recorded transaction details, does each row include the detail of the transaction as a whole, or each individual item that was purchased? The latter would have a more detailed grain.
While fact tables include information on specific actions, a dimension table, on the other hand, includes non-transactional information that relates to the fact table. These are the items of interest in analytics: data on each individual customer, location/branch, employee, product, etc. In other words, the dimension is the lens through which you can examine and analyze the fact data.
There are typically far fewer facts, which are “linked” to the various dimension tables, forming a structure that resembles a star, hence the term star schema.
A snowflake schema is similar to the star schema. The main difference is that in a snowflake schema, the dimension tables are normalized--that means that the individual dimension tables from the star schema are re-organized into a series of smaller, sub-dimension tables which reduces data redundancy. This is done so that the same information isn’t stored in multiple tables, which makes it easier to change or update the information since it only has to be change in one location. The downside of the snowflake schema is that it can be complicated for users to understand, and requires more code to generate a report. Sometimes it is best to maintain a de-normalized star schema for simplicity’s sake.
Conclusion
These are just the basics of how data flows into a data warehouse, and how a warehouse could be structured. While the star and snowflake schemas are not the only way (there is also a newer schema called a Data Vault), they do provide a standardized way to store and interact with historical data. Ultimately, a well-organized data warehouse allows data scientists and analysts to more easily explore data, ask more questions, and find the answers they need in a more timely fashion.
Why Using a Data Warehouse Optimizes Analytics
Beginning an analytics project is no small task. After choosing the initial question to be answered and formulating a plan of actions to be taken as a result, the next logical step is to complete an inventory of the available data sources and determine what data is needed to reach the decided-upon analysis goal.
It’s common for a company to have many different databases containing a wide variety of information. To gain a complete view of of a company through analytics, data from many sources is aggregated to one place. A company may have transaction data in one database, customer information in another, and website activity logs in yet another. Bringing all of this data together is a critical part of any analytics project; however, it poses two major challenges.
The first challenge: data is messy. When aggregating data from different sources, the formatting of data points is frequently inconsistent, data may be missing from multiple fields, or the databases may have completely different schemas. In order to build any kind of predictive model or historical analysis, data must be cleaned and organized. This process can be very difficult and time consuming.
The second challenge: analytics requires hardware and software that is powerful and flexible. Most business people have experience running reports and looking at short-term trends. However, data scientists are looking at the bigger picture. They may be sifting through months, or even years, worth of data to uncover trends.
This means that for an analytics project, the data must be stored in a system that has the ability and computing power to comb through thousands of rows of data. The system must also allow data scientists and analysts the flexibility to run a wide variety of queries. Advanced analytics is a journey of discovery; the question being answered may evolve over time as new trends are discovered. Each inquiry leads to new questions as the company journeys deeper into analytics.
Because of these constraints, it is important to consider the physical and virtual structure surrounding the data. Setting up the most efficient structure for the job at hand is the best way to optimize any project. We will go through two ways to manage data for analytics:
One Way to Do It
Data cleaning and linking is time-consuming. In the interest of time, it may seem that the quickest way to get a desired answer is to prepare only the data that is actually needed for a given analysis. Data scientists spend large amounts of time preparing the data, so why waste time aggregating, cleaning and linking data that won’t be used?
Because analytics never stops at a single question and answer (and, as software engineers know, requirements often change many times before the final product is released), a project-specific cleaned and linked dataset may need to be altered many times. A subsequent or new question may involve the use of additional or completely different data points. The relevant data must be cleaned, linked, and organized from the source databases all over again. This especially becomes an issue when the question at hand requires the most up-to-date information. Each time new data is included, the dataset must be updated or completely re-generated and linked. Think of how many new, ad hoc datasets would be created from source data over the lifetime of the analytics project!
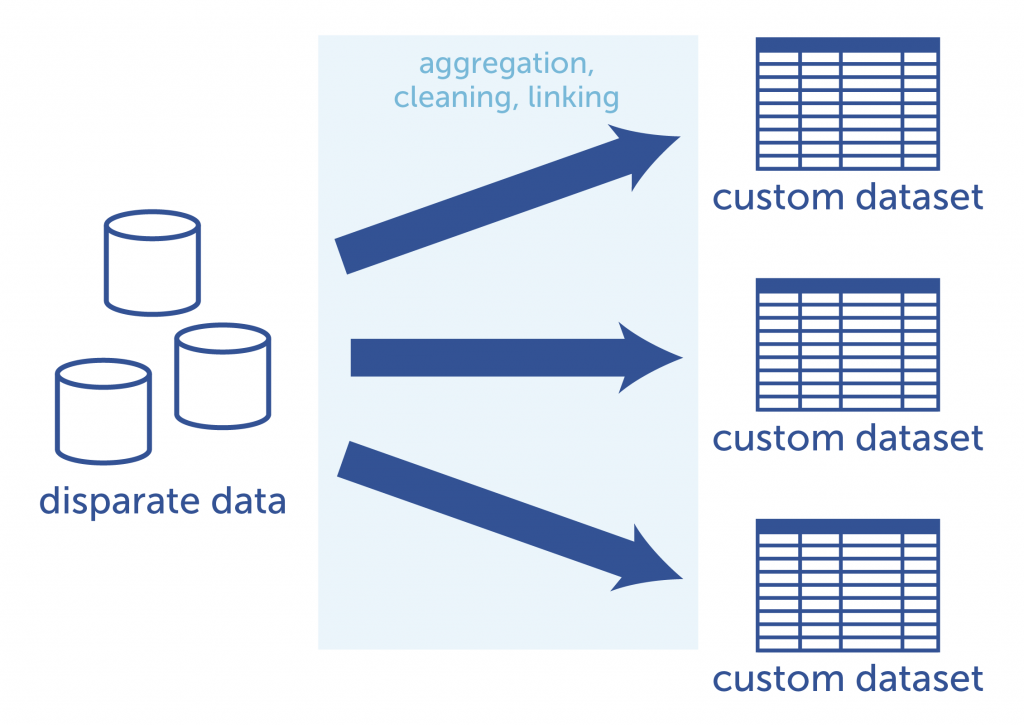
Each analytics project requires a new custom dataset to be created from
the source databases. This requires time and effort to achieve.
A Better Way
It is important to think of the bigger picture when it comes to data analysis. It is highly unlikely that an analyst or data scientist will ever stop with one question. So, instead of creating specialized datasets for analysis on an ad hoc basis, it is more efficient in the long run to create an integrated, linked, and cleaned data warehouse to house the entirety of the data. From there, a data scientist or analyst can build custom datasets for their analyses. Because the data is pre-cleaned and stored in an organized manner, it is relatively simple for a data scientist or analyst to select the pieces of information needed to create an analytics-ready dataset on the fly.
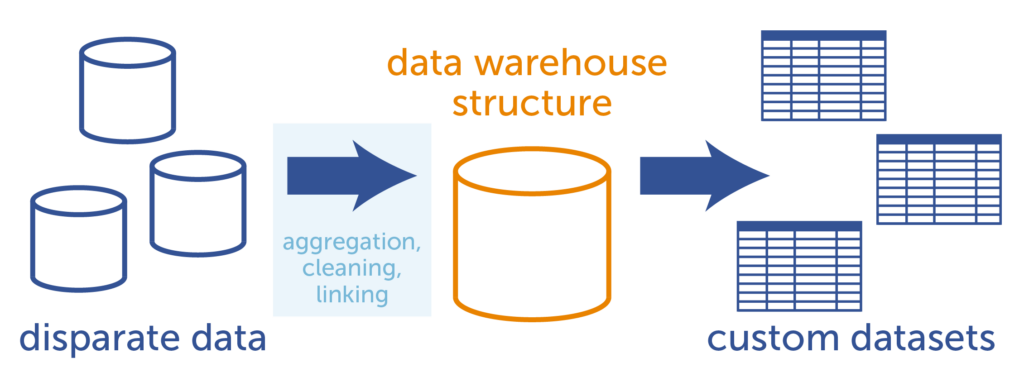
With a data warehouse, the disparate data is aggregated, cleaned, and linked into a single database structure.
From there, custom datasets for analytics are generated more easily.
Data Warehouse vs. Transactional Databases
The term “data warehouse” refers to a philosophy on creating a relational database system that is optimized for query operations and analyses. This differs from other database systems in a number of ways.
Most organizations that are collecting data have at least one (and sometimes many) online transaction processing (OLTP) databases. An OLTP database is used to collect transactional data, and is designed to work well when new records are added frequently, in real time. An example would be a database that collects website click information, or logs every time a customer makes a purchase. These databases give users the ability to perform only a few, set operations because the majority of the computing workload is devoted to recording new transactions in real-time. To keep an OLTP database at top speed, older data is frequently archived. Since analytics requires historical data and the ability to run a variety of exploratory operations on the data, this is not the ideal type of environment for an analysis to occur.
A data warehouse, on the other hand, is focused on analysis rather than recording data in real-time. This give the analyst or data scientist the computing power and flexibility needed to explore historical data to find deeper trends.
There are four guiding principles for data warehouse systems, as defined by the father of data warehousing, William Inmon:
- Subject-oriented: The structure of a data warehouse is centered around a specific subject of interest, rather than as a listing of transactions organized by timestamps. For instance, a data warehouse might have the transactions organized, instead, by the customer who made the transaction. (This would be what we call an “atom-centric” view, with the customer as an atom.) An analyst or data scientist can look for trends in customer transactions over time, and draw comparisons between similar customers and their transaction histories.
- Integrated: In a data warehouse, data from multiple sources is integrated into a single structure and consistent format. In the process of integration, naming conflicts are resolved, units of measure are converted into a consistent format, and missing data may be replaced.
- Non-volatile: A data warehouse is a stable system. Unlike an OLTP database, data is not constantly being added or changed.
- Time-variant: The term “time-variant” refers to the inclusion of historical data for analysis of change over time. Since a data warehouse includes all data rather than just a snapshot of the most recent transactions, a data scientist can begin to search long-term trends.
As you can see, there are many benefits to using a data warehousing system for analytics. The idea was conceived with analytics in mind, and this type of database structure can speed the time to insights, especially when pursuing subsequent analytics projects. A data warehouse allows data scientists and analysts to spend more time deeply exploring the data, rather than wasting precious hours on data preparation.
Conclusion
Building a data warehouse is the best long-term solution for an advanced analytics program. But how does a data warehouse work, and how to data scientists go about building them? Stay tuned. In a future blog post, we will discuss some of the more technical aspects of data warehouses: how they are built and updated; and the various ways to structure the data to optimize analytics.
Decision Trees: An Overview
Introduction
If you’ve been reading our blog regularly, you have noticed that we mention decision trees as a modeling tool and have seen us use a few examples of them to illustrate our points. This month, we’ve decided to go more in depth on decision trees—below is a simplified, yet comprehensive, description of what they are, why we use them, how we build them, and why we love them. (Does that make us the tree-huggers of the digital age? Maybe!)
What is a Decision Tree?
A decision tree is a popular method of creating and visualizing predictive models and algorithms. You may be most familiar with decision trees in the context of flow charts. Starting at the top, you answer questions, which lead you to subsequent questions. Eventually, you arrive at the terminus which provides your answer.
Decision trees tend to be the method of choice for predictive modeling because they are relatively easy to understand and are also very effective. The basic goal of a decision tree is to split a population of data into smaller segments. There are two stages to prediction. The first stage is training the model—this is where the tree is built, tested, and optimized by using an existing collection of data. In the second stage, you actually use the model to predict an unknown outcome. We’ll explain this more in-depth later in this post.
It is important to note that there are different kinds of decision trees, depending on what you are trying to predict. A regression tree is used to predict continuous quantitative data. For example, to predict a person’s income requires a regression tree since the data you are trying to predict falls along a continuum. For qualitative data, you would use a classification tree. An example would be a tree that predicts a person’s medical diagnosis based on various symptoms; there are a finite number of target values or categories. It would be tempting to simply conclude that if the information you are trying to predict is a number, it is always a regression tree, but this is not necessarily the case. Zip code is a good example. Despite being a number, this is actually a qualitative measure because zip codes are not calculated; they represent categories.
Key Terms
Before we cover the more complex aspects of decision trees, let’s examine some key terms that will be used in this post. It is important to note that there are multiple terms used to describe these concepts--however, these are the ones that we use at Aunalytics, and we will use these for the duration of this blog post for consistency. However, the alternate terms will be noted as well, in case you encounter them in a different context.
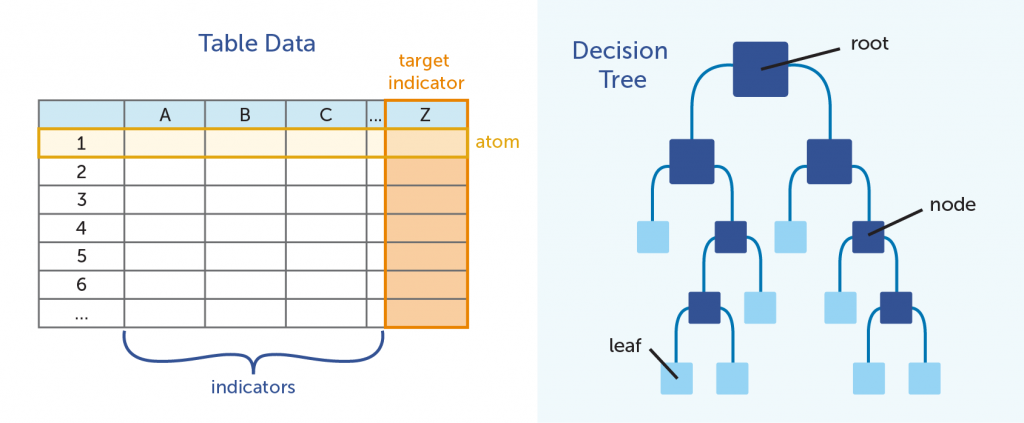
In the table above, Column Z is the target indicator; the piece of information that is being predicted by the model. All modeling is with regards to these data points. Alternate terms: class, predicted variable, target variable
The data in columns A, B, C, and so on are called indicators. The indicators are the data points that are used to to make predictions. Alternate terms: feature, dimension, variable
As a whole, the total collection of indicators forms an indicator vector. Alternate terms: measurement vector, feature vector, dataset
Rows 1, 2, and 3 represent what we refer to as atoms. Each row contains data points as they relate to a singular entity; in our analyses, typically this is an individual person or product. We talked about the atom in a previous blog post. Alternate terms: instances, examples, data points
Unlike a tree you would see outside your window, decision trees in predictive analytics are displayed upside down. The root of the tree is on top, with the branches going downward.
Each split in the branch, where we break the large group into progressively smaller groups by posing an either-or scenario, is referred to as a node. The a terminal node is called a leaf.
Methodology
As mentioned previously, building a predictive model involves first training the model (and building the tree) by using known data and verifying its accuracy and reliability by using the model on test data that had been set aside to predict the known test outcomes. In the diagram below, the model is initially built using 6 months’ worth of data (the 6th month is the target indicator, and the five months before that are used to train the model that will predict the 6th month’s outcome). The model is evaluated for accuracy and optimized by using the previous month’s data to predict the known outcome for today (a known value). Finally, the model can be used to predict outcomes in the future.
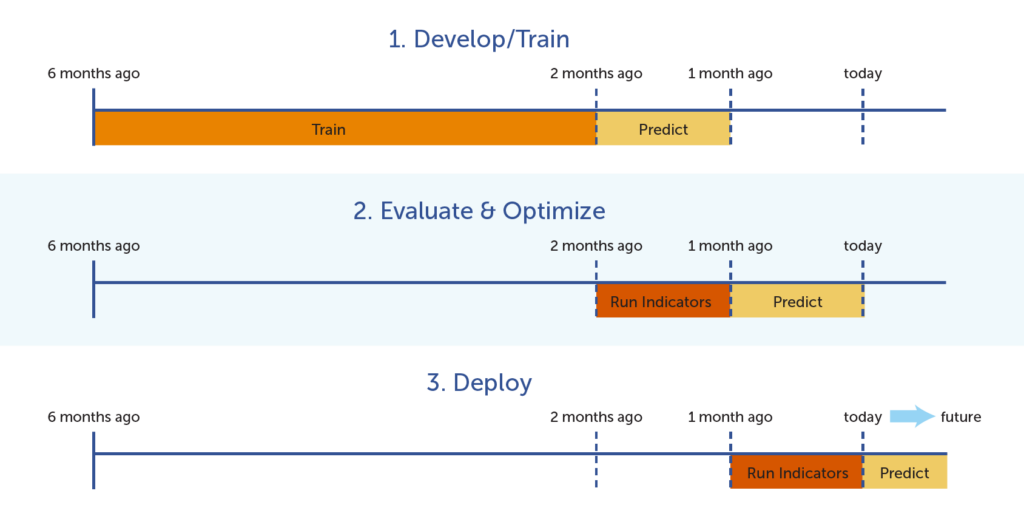
Once the tree has been tested and optimized, it can be used to predict unknown or future outcomes.
Development
When it comes to actually building a decision tree, we start at the root, which includes the total population of atoms. As we move down the tree, the goal is to split the total population into smaller and smaller subsets of atoms at each node; hence the popular description, “divide and conquer.” Each subset should be as distinct as possible in terms of the target indicator. For example, if you are looking at high- vs. low-risk customers, you would want to split each node into two subsets; one with mostly high-risk customers, and the other with mostly low-risk customers.
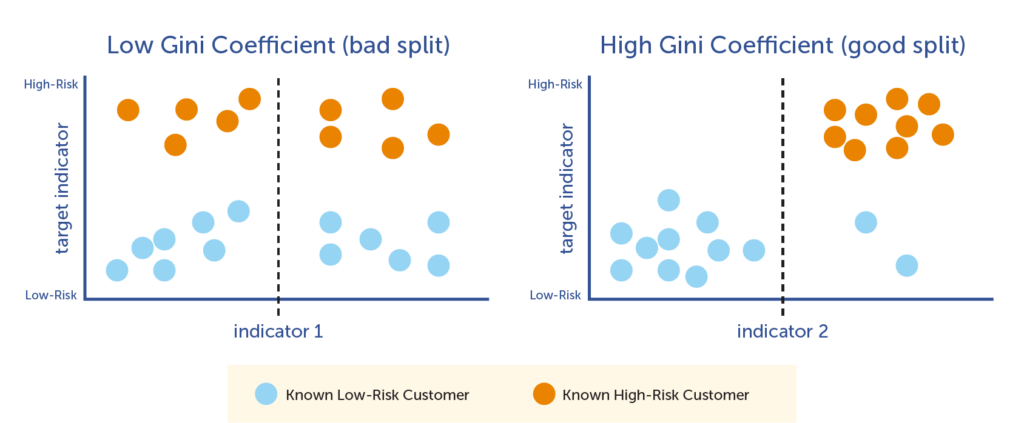
This goal is achieved by iterating through each indicator as it relates to the target indicator, and then choosing the indicator that best splits the data into two smaller nodes. As the computer iterates through each indicator-target pair, it calculates the Gini Coefficient, which is a mathematical calculation that is used to determine the best indicator to use for that particular split. The Gini Coefficient is a score between 0 and 1, with 1 being the best split, and 0 being the worst. The computer chooses the indicator that has the highest Gini Coefficient to split the node, and then moves on to the next node and repeats the process.
In the following illustration, you can see how the graph on the right, showing indicator 1 in terms of the target indicator, is not an optimal split. There are almost equal amounts of both high- and low-risk customers on each side of the split line. However, the graph on the left shows a very good indicator; the line splits the high- and low-risk customers very accurately.
How to calculate a predictive score
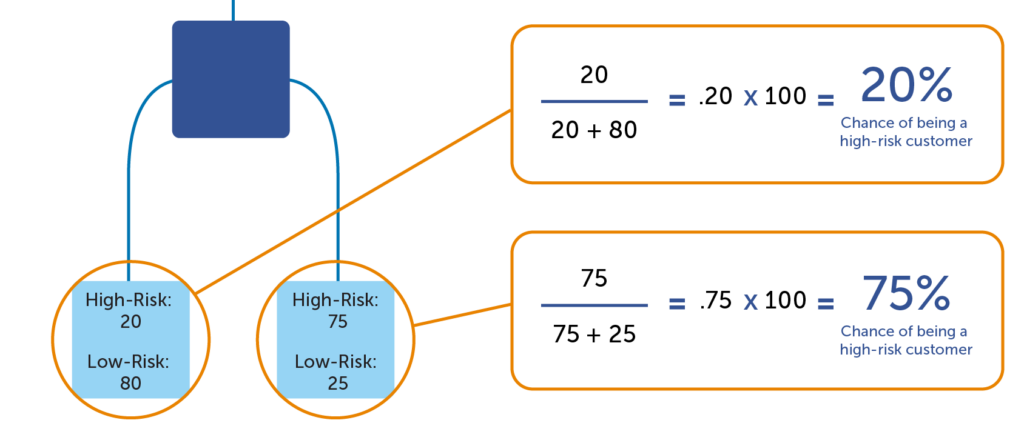
Once the computer program has finished building the tree, predictive scores can be calculated. The predictive score is a percentage of the target indicator in the terminal node (or leaf) of the trained model. In the example below, there are 20 high-risk customers and 80 low-risk customers in the leaf to the far left. Any atom that ends up in the left leaf would be said to have a 20% chance of being a high-risk customer (20 / (20 + 80) = 20%). But for the leaf on the right, a customer would have a 75% chance of being a high-risk customer (75 / (75 + 25) = 75%). This demonstrates that a model can predict whether certain atoms have a higher propensity to a target indicator. It is important to remember that it is a prediction, which is not 100% accurate (we’re not psychics!) However, it’s a much more accurate than a random guess, which is enough to make a huge difference!
Optimizing the Model
How to reduce bias
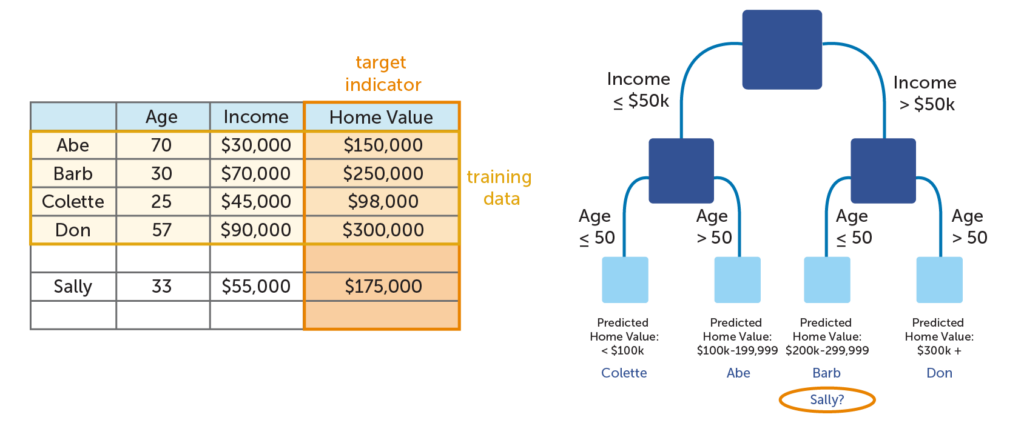
There is one major potential pitfall when working with decision trees, and that is creating an overly-complex tree. With decision trees, simplicity is the key to reducing bias. If a tree grows too large, it ceases to be useful. The image below illustrates this point with a very simplified example. As you can see, the model splits the data in such a way that the bottom leaves only have one person each. All this tree does is show the information in the table in a new way. It adds no additional insight; it only restates the data. You will also notice that the tree is fairly inaccurate; if you add Sally’s data to the mix, you see that it predicts that she has a much more expensive home value than she actually does. The tree has failed to allow for novel circumstances outside of the training data. This is known as overfitting (or overlearning).
The challenge, then, is to create a tree that is specific enough to allow for actionable insights, yet not complex to the point where it does not give any new information or allow for possibilities that were not expressly stated in the data. This problem is alleviated through a process known as pruning.
The idea behind pruning is to build a very complex tree, and then take away enough levels of complexity until it is as simple as possible, yet still maximally accurate in predicting the target indicator. This is done by employing a simple technique that was mentioned earlier in this post: set aside a portion of the training data to be used as validation data. Since this data was not used to train the model, it will show whether or not the decision tree has overlearned the training data. If the predictive accuracy (also known as lift) with the test data are low, the size of the tree is reduced, and the process is repeated until the tree reaches the sweet spot between high accuracy and low complexity.
How to knock it out of the park
By now, you’ve learned how decision trees are built to ensure accuracy of results, while avoiding overfitting. But how do data scientists take a predictive model to the next level? Use multiple models! When multiple models are combined into a single mega-model, it is referred to as an ensemble model. Using an ensemble of predictive models can improve upon a single model’s performance by anywhere from 5-30%. That’s huge! There are a few ways of creating an ensemble, but we will discuss two common methods: bagging and random forests.
Bagging is a shortened version of the term “bootstrap aggregating.” In this method, the training data is split into smaller subsets of data, and within the subsets, some atoms are randomly duplicated or removed. This ensures that no single atom disproportionately affects the final results. A decision tree is created for each subset, and the results of each tree are combined. By combining these trees into an ensemble model, the shortcomings of any single tree are overcome.
Random forests are closely related to bagging, but add an extra element: instead of only randomizing the atoms in the various subsets of data, it also randomly duplicates or deletes indicators. If a certain indicator is flawed or shows a false correlation with the target indicator, it is overcome by the fact that the flawed indicator is not present in certain trees, or is reduced in importance in others.
Conclusion
Hopefully now you have a better understanding of decision trees; why they are used frequently in predictive modeling, how they are created, and how they can be optimized for best results. Decision trees are a powerful tool for data scientists, but they must be handled with care. Although much of the repetitive tasks are achieved by use of computers (hence the term machine learning), all aspects of the process must be orchestrated and overseen by an experienced data scientist in order to create the most accurate model. But the work is well worth the effort in the end when an accurate model leads to actionable insights.
Note: If you are interesting in learning more about decision trees and predictive modeling, we would recommend the book Predictive Analytics by Eric Siegel, or the article “How to Grow and Prune a Classification Tree” by David Austin (which goes into greater detail on the mathematical explanations).
