Data has long been used in decision making in the financial services industry. Statistical scoring models based on consumer data like FICO® have been used for half a century to guide lending decisions in the financial services sector. But today’s analytics space has evolved to the point where many other factors not easily digested by credit scoring bureaus play a roll. Imagine a deeper understanding of lending risk factors not commonly reported in credit scores:
- Number of changes of residence in the past five years
- Householding status (single or cohabiting/married)
Imagine having the ability to look at a particular client and understand based on past data how that individual compares in terms of various factors driving that business relationship:
- Which of our financial products is this customer most likely to choose next?
- How likely is this customer to default or become past due on a mortgage?
- What is churn likelihood for this customer?
- What is the probable lifetime value of this customer relationship?
Aunalytics financial services experts understand the most pressing business questions specific for this industry. Working with our financial services experts, Aunalytics’ Innovation Lab data scientists have developed proprietary machine learning, AI and deep learning algorithms based on a solid understanding of the data commonly collected by financial institutions. Our data engineers understand the types of data commonly created and used by the industry, common data sources and have created integrations to bring data from across a bank together into a single analytics-ready feed. The end result is data organized into industry specific relational data marts ready to answer questions posed by business users from financial services institutions.
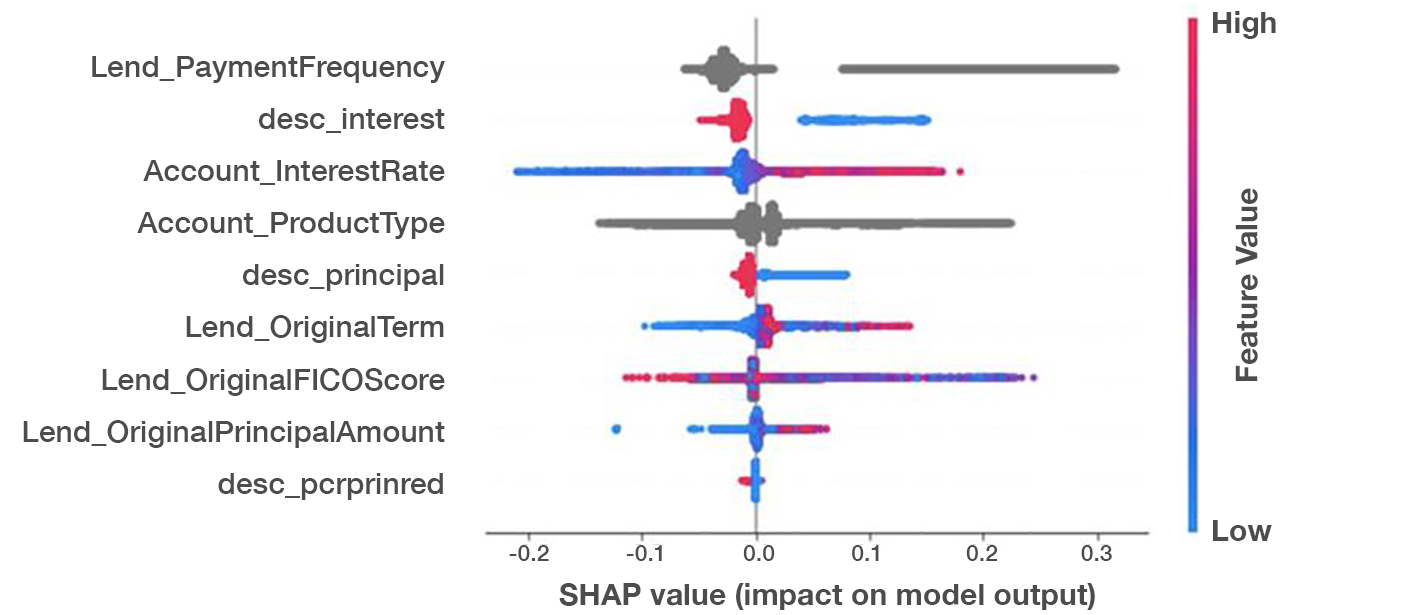
A SHAP value chart for a remarkably accurate loan default risk model we developed. A benchmark with testing data provided by one client was able to predict 30% of that customer’s loan defaults with 99% accuracy, or predict 75% of all loan defaults with 75% accuracy (i.e. 0.99 precision at 0.3 recall or 0.75 precision at 0.75 recall).
Take the example of a recent model we developed at Aunalytics to predict loan default risk. Looking at a chart of the SHAP (Shapley Additive Explanations) values for this model, we can see a number of common-sense observations confirmed. For example, high interest loans (represented by a pink dot in the Account_InterestRate line) and low FICO scores (represented by a blue dot in the Lend_OriginalFICOScore) positively correlate with default risk. This model discovered some much less intuitive characteristics of high risk loans as well: For some loans, payment frequency (Lend_PaymentFrequency) was actually the single most important factor for predicting loan defaults. Moreover, a well-known but not always properly appreciated factor to default risk is illustrated visually: the type of loan being underwritten (Account_ProductType) is in many cases just as important as a customer’s credit score to default risk. Auto loan applicants with high FICO scores might be more of a default risk than customers with low credit scores shopping for a home mortgage.
In so many cases, machine learning techniques enable more accurate and understandable models of risk, propensity, and customer churn because they represent a more complex model understanding of the various factors that go into risk modeling. Our models deliver greater accuracy than simpler, statistical models because they understand the relationship between multiple indicators.
Through AI and machine learning enriched data points, clients can easily understand a particular customer or product by comparing it to other customers with similar data. Whether you want to know if a customer is likely to select a new product, their default risk, churn likelihood, or any other number of questions, our data scientists and business analysts are experienced and committed to answering these questions based on years of experience with financial services businesses.
